Building Queries¶
In this panel, the user constructs queries by adding filters (these will be explained more thoroughly in a moment). There are two key concepts that drive a query in SCT:
Linguistic Object A linguistic object can be an utterance, word, or phone. By selecting a linguistic object, the user is specifying the set of elements over which the query is to be made. For example, selecting “phones” will cause the program to look for phones with properties specified by the user (if “words” were selected, then the program would look for words, etc.)
Filters Filters are statements that limit the data returned to a specific set. Each filter added provides another constraint on the data. Click here for more information on filters. Here’s an example of a filter:

This filter specifies all the object (utterance, phone, syllable) which are followed by an object of the same type that shares its rightmost boundary with a word.
Now you’re ready to start building queries. Here’s an overview of what each dropdown item signifies
Linguistic Objects¶
- Utterance: An utterance is (loosely) a group of sounds delimited by relatively long pauses on either side. This could be a clause, sentence, or phrase. Note that utterances need to be encoded before they are available.
- Syllables Syllables currently have to be encoded before this option is available. The encoding is done through maximum attested onset
- Word: A word is a collection of phones that form a single meaningful element.
- Phone: A phone is a single speech segment.
The following is avaiable only for the TIMIT database:
- surface_transcription This is the phonetic transcription of the utterance
Filters¶
Filters are conditions that must be satisfied for data to pass through. For example
is a filter
Many filters have dropdown menus. These look like this:
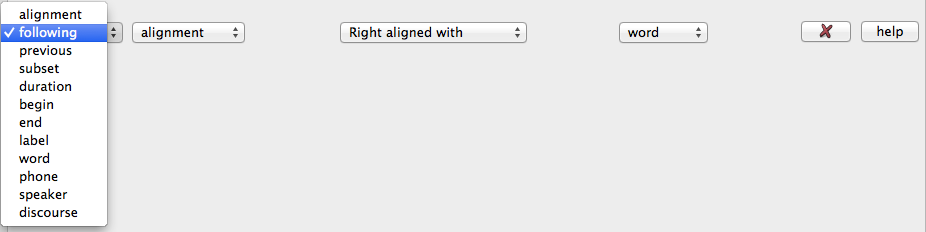
Generally speaking, the first dropdown menu is used to target a property. These properties are available without enrichment for all databases:
- alignment The position of the object in a super-object (i.e. a word in an utterance, a phone in a word...)
- following Specifies the object after the current object
- previous Specifies the object before the current object
- subset Used to delineate classes of phones and words. Certain classes come premade. Others are avaiable through enrichment
- duration How much time the object occupies
- begin The start of the object in time (seconds)
- end The end of the object in time (seconds)
- label The orthographic contents of an object
- word Specifies a word (only available for Utterance, Syllable, and Phone)
- syllable Specifies a syllable
- phone Specifies a phone
- speaker Specifies the speaker
- discourse Specifies the discourse, or file
- category Only available for words, specifies the word category
- transcription Only available for words, specifies the phonetic transcription of the word in the corpus
These are available after enrichment:
- utterance Available for all objects except utterance, specifies the utterance that the object came from
- syllable_position Only available for phones, specifies the phone’s position in a syllable
- num_phones Only available for words, specifies the number of phones in a word
- num_syllables Only available for words, specifies the number of syllables in a word
- position_in_utterance Only available for words, specifies the word’s index in the utterance
These are only available for force-aligned database:
- manner_of_articulation Only available for phones
- place_of_articulation Only available for phones
- voicing Only available for phones
- vowel_backness Only available for phones
- vowel_rounding Only available for phones
- vowel_height Only available for phones
- frequency Only available for words, specifies the word frequency in the corpus
- neighborhood_density Only available for words, specifies the number of phonological neighbours of a given word.
- stress_pattern Only available for words, specifies the stress pattern for a word
- The second filter will depend on which filter you chose in the first column. For example, if you chose phone you will get all of the phone options specified above. However if you choose label you will be presented with a different type of dropdown menu. This section covers some of these possibilities.
alignment
- right aligned with This will filter for objects whose rightmost boundary lines up with the rightmost boundary of the object you will select in the third column of dropdown menus (utterance, syllable, word, or phone).
- left aligned with This will filter for objects whose leftmost boundary lines up with the left most boundary of the object you will select in the third column of dropdown menus (utterance, syllable, word, or phone).
- not right aligned with This will exclude objects whose rightmost boundary lines up with the rightmost boundary of the object you will select in the third column of dropdown menus (utterance, syllable, word, or phone).
- not left aligned with This will exclude objects whose leftmost boundary lines up with the left most boundary of the object you will select in the third column of dropdown menus (utterance, syllable, word, or phone).
- subset
- == This will filter for objects that are in the class that you select in the third dropdown menu.
begin/end/num_phones/num_syllables/ position_in_utterance/frequency/ neighborhood_density/duration
- == This will filter for objects whose property is equal to what you have specified in the text box following this menu.
- != This will exclude objects whose property is equal to what you have specified in the text box following this menu.
- >= This will filter for objects whose property is greater than or equal to what you have specified in the text box following this menu.
- <= This will filter for objects whose property is less than or equal to what you have specified in the text box following this menu.
- > This will filter for objects whose property is greater than what you have specified in the text box following this menu.
- < This will filter for objects whose property is less than what you have specified in the text box following this menu.
stress_pattern/category/label/ speaker + name/discourse + name/ transcription/vowel_height/ vowel_backness/vowel_rounding/ manner_of_articulation/ place_of_articulation/voicing
- == This will filter for objects whose property is equivalent to what you have specified in the text box or dropdown menu following this menu.
- != This will exclude objects whose property name is equivalent to what you have specified in the text box or dropdown menu following this menu.
- regex This option allows you to input a regular expression to match certain properties.
Experiment with combining these filters. Remember that each time you add a filter, you are applying further constraints on the data.
- Some complex queries come pre-made. These include “all vowels in mono-syllabic words” and “phones before word-final consonants”. Translating from English to filters can be complicated, so here we’ll cover which filters constitute these two queries.
All vowels in mono-syllabic words
Since we’re looking for vowels, we know that the linguistic object to search for must be “phones”
To get mono-syllabic words, we have to go through three phases of enrichment
- First, we need to encode syllabic segments
- Second, we need to encode syllables
- Finally, we can encode the hierarchical property: count of syllables in word
Now that we have this property, we can add a filter to look for monosyllabic words:
word: count_of_syllable_in_word == 1- Notice that we had to select “word” for “count_of_syllable_in_word” to be available
The next filter we want to add would be to get only the vowels from this word.
subset == syllabic- This will get the syllabic segments (vowels) that we encoded earlier
Phones before word-final consonants
Once again, it is clear that we are looking for “phones” as our linguistic object.
The word “before” should tip you off that we will need to use the “following” or “previous” property.
We start by getting all phones that are in the penultimate position in a word.
following phone right-aligned with word- This will ensure that the phone after the one we are looking for is the word-final phone
Now we need to limit it to consonants
following phone subset != syllabic- This will further limit the results to only phones before non-syllabic word-final segments (word-final consonants)