Filters Explained¶
So far, there has been a lot of talk about objects, filters, and alignment, but these can be a difficult-to-grasp concepts. These illustrated examples might be helpful in gleaning a better understanding of what is meant by “object”, “filter” and “alignment”.
The easiest way to start is with an example. Let’s say the user wanted to search for word-final fricatives in utterance-initial words
While to a person this seems like a fairly simple task that can be accomplished at a glance, for SCT it has to be broken up into its constituent steps. Let’s see how this works on this sample sentence:
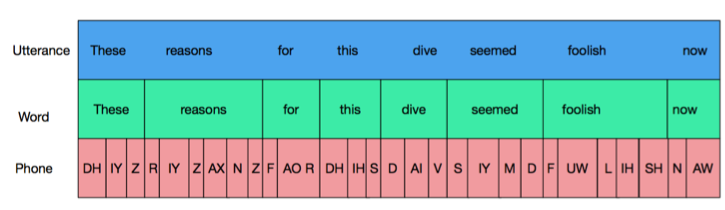
Here, each level (utterance, word, phone) corresponds to an object. Since we are ultimately looking for fricatives, we would want to select “phones” as our linguistic object to find.
Right now we have all phones selected, since we haven’t added any filters. Let’s limit these phones by adding the first part of our desired query: word-final phones. To accomplish this, we need to grasp the idea of alignment.
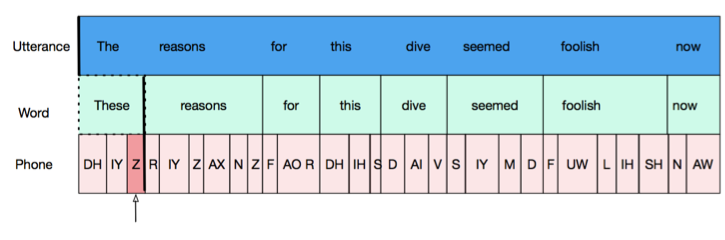
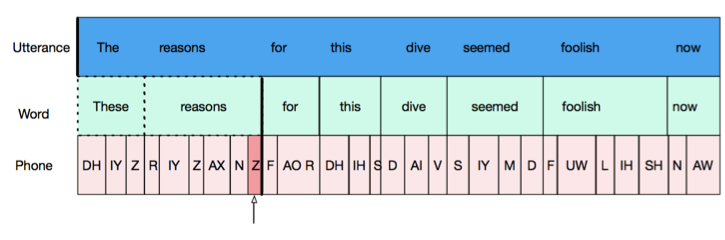
Each object (utterances, words, phones) has two boundaries, left and right. These are represented by the walls of the boxes containing each object in the picture. To be “aligned”, two objects must share a boundary. For example, the non-opaque objects in the next 2 figures are all aligned. Shared boundaries are indicated by thick black lines. Parent objects (for example, words in which a target phone is found) are outlined in dashed lines. In the first picture, the words and phones are “left aligned” with the utterance (their left boundaries are the same as that of the utterance) and in the second image, words and phones are “right aligned” with the utterance.
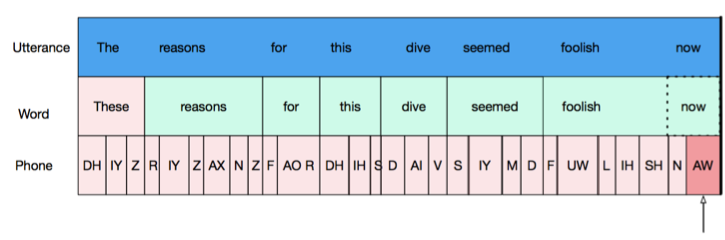
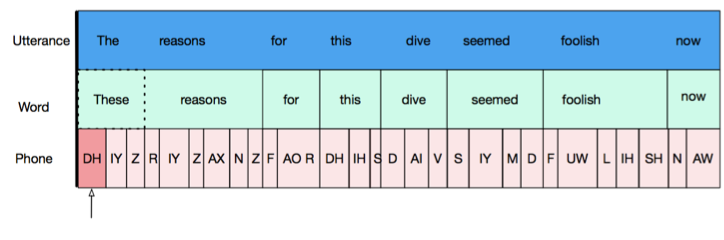
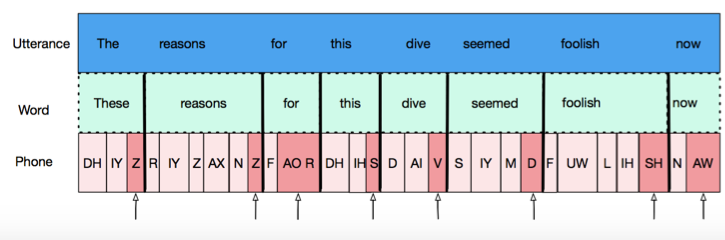
Now that we understand alignment, we can use it to filter for word-final phones, by adding in this filter:

By specifying that we only want phones which share a right boundary with a word, we are getting all word-final phones.
However, recall that our query asked for word-final fricatives, and not all phones. This can easily be remedied by adding another filter *:
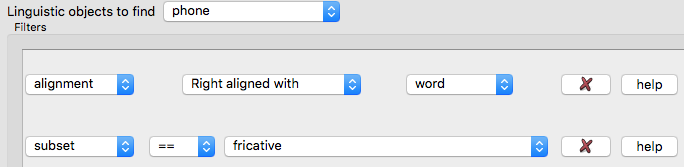
* NB the “fricative” property is only available through enrichment.
Now the following phones are found:
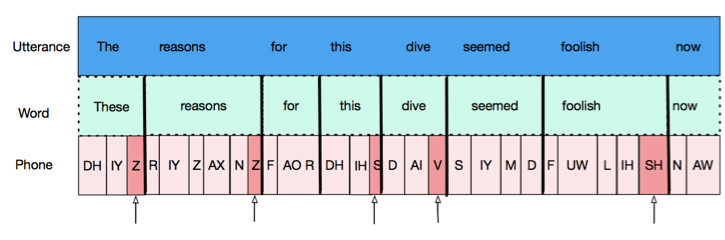
Finally, in our query we wanted to specify only utterance-intial words. This will again be done with alignment. Since English reads left to right, the first word in an utterance will be the leftmost word, or the word which shares its leftmost boundary with the utterance. To get this, we add the filter:

This gives us the result we are looking for: word-final fricatives in utterance-initial words
Another thing we can do is specify previous and following words/phones and their properties. For example: what if we wanted the final segment of the second word in an utterance?
This is where the “following” and “previous” options come into play. We can use “previous” to specify the object before the one we are looking for. If we wanted the last phone of the second word in our sample utterance (the “s” in “reasons”) we would want to specify something about the previous word’s alignment. If we wanted to get the final phone of the words in this position, our filters would be:

For a full list of filters and their uses, see the section on building queries